
使用LLaMA-Factory进行大模型微调
平台选择
选用的平台是阿里云人工智能平台PAI,新人注册有免费使用额度,配置是8CPU/32G内存以及一个V100显卡,用来跑一些参数来较小的模型是足够的。主要任务是LLM-as-Judge,也就是使用大模型作为裁判评判其余模型结果的好坏。
开通PAI平台的过程就不说了,这个是配环境的代码,需要注意的是torch的版本,下错了版本cuda没法用
1 | git clone https://github.com/hiyouga/LLaMA-Factory.git |
模型选择
模型选择最开始尝试了chatGLM6B的模型,但是后来意识到参数量依旧过高,而且动不动系统盘就爆满,因此转向使用小模型,尝试了Qwen1.5-1.8B模型,最开始在PandaLM数据集上的效果惊为天人,20轮Tuning后在测试集上的准确率高达78%,但是后来尝试了其余数据集,准确率都在50%左右徘徊,效果不甚理想。于是转为使用Phi3模型。
LLaMA-Factory自带一个UI界面,不用自己写代码,只需要调配一下参数就可以自动微调。
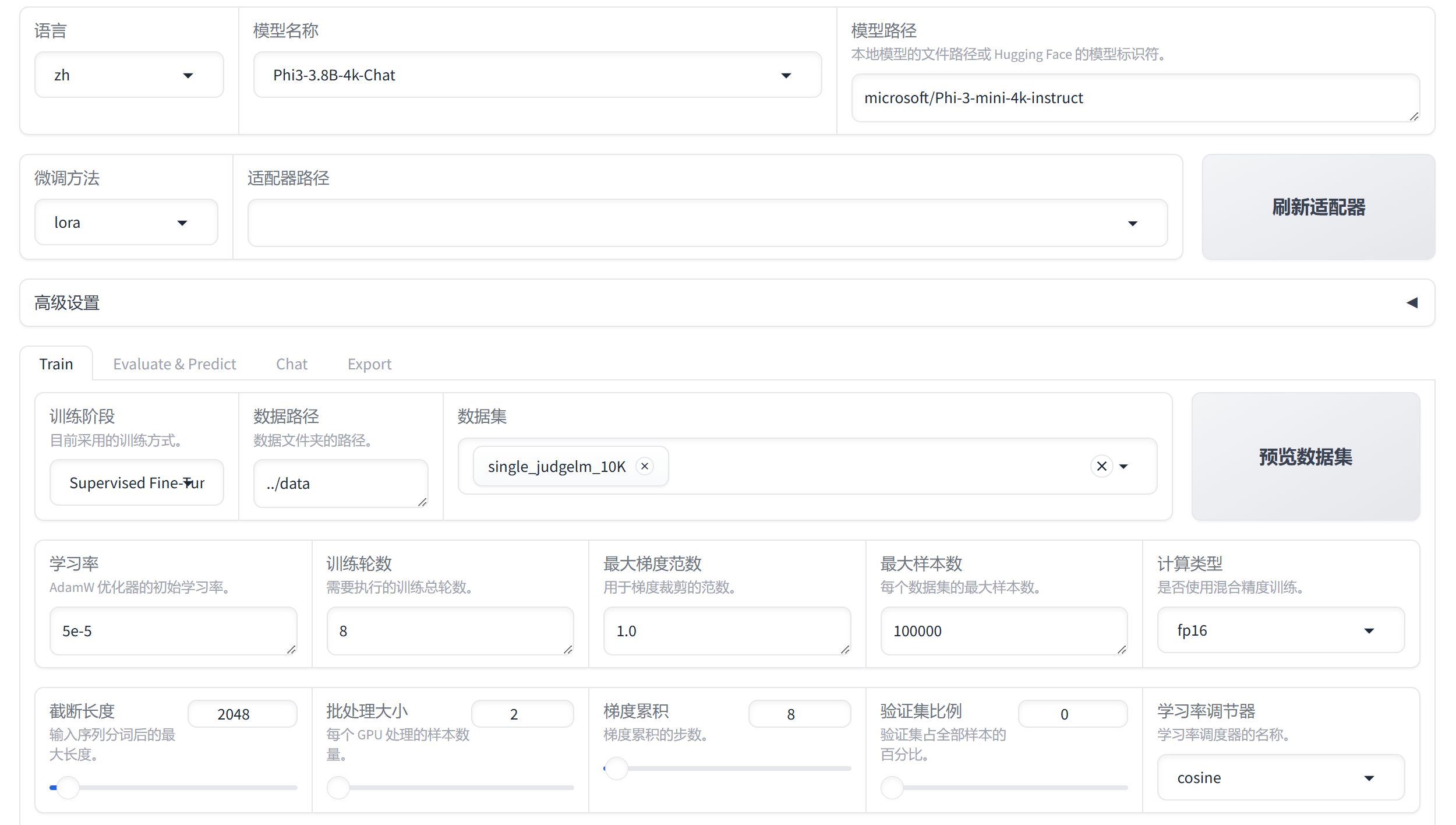
然后在运行后出现报错:

原因是无法连接到huggingface,我以为是云平台网络的问题,ping了一下huggingface.co,果然ping不通。没办法,只能先把模型下载到本地再进行微调。
1 | git clone https://www.modelscope.cn/LLM-Research/Phi-3-mini-4k-instruct.git |
然后修改一下模型路径即可。
数据集处理
训练集
采用的JudgeLM数据集作为训练集,原数据集是Pairwise Comparison,需要转化为Single answer grading的格式,转化后的数据集格式预览如下:

点击开始后便开始微调了
面板右侧有训练的loss图,训练结束后还可以查看验证集的loss,用来判断是否过拟合(该实验中验证集的比率设置为0.1)
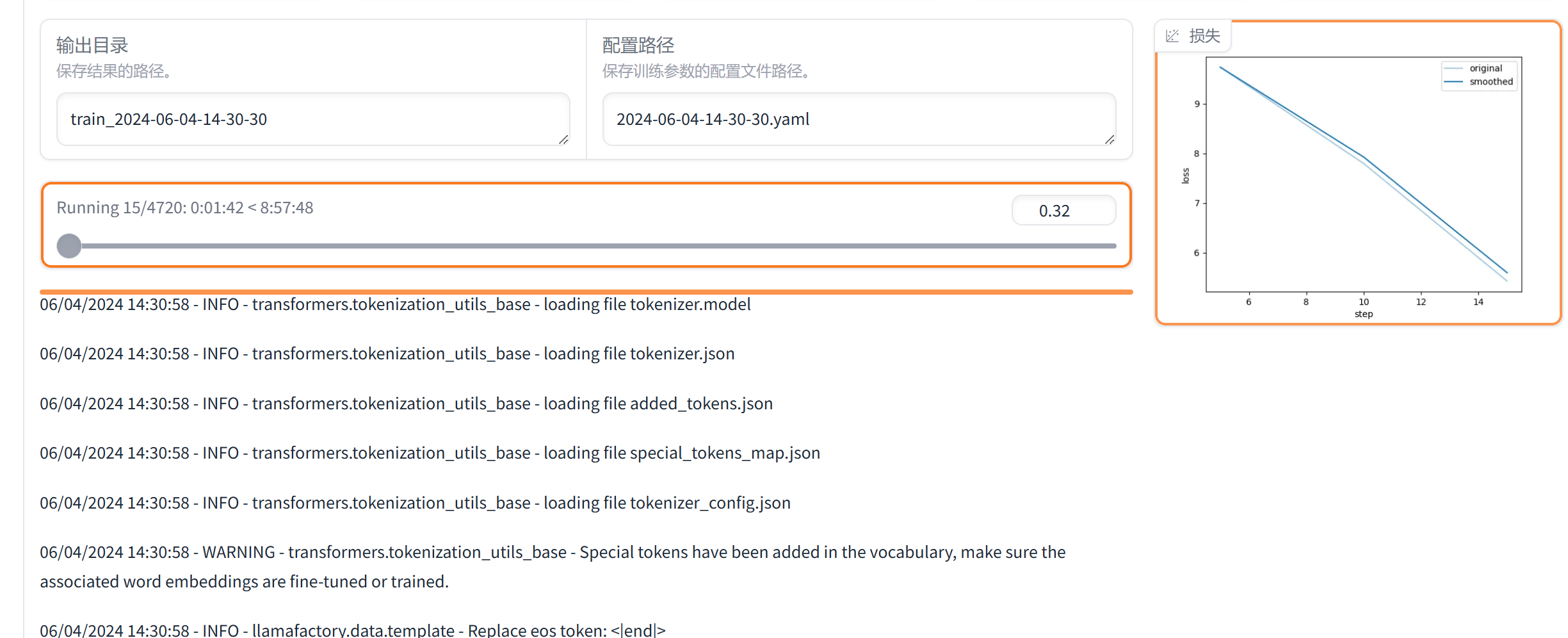
看了一下训练8轮需要训9个小时,开着慢慢跑吧,趁着模型在跑的时候处理一下测试集数据
测试集
预计在四个benchmark上进行跑分,分别是autoj、pandalm、llmbar、mtbench。
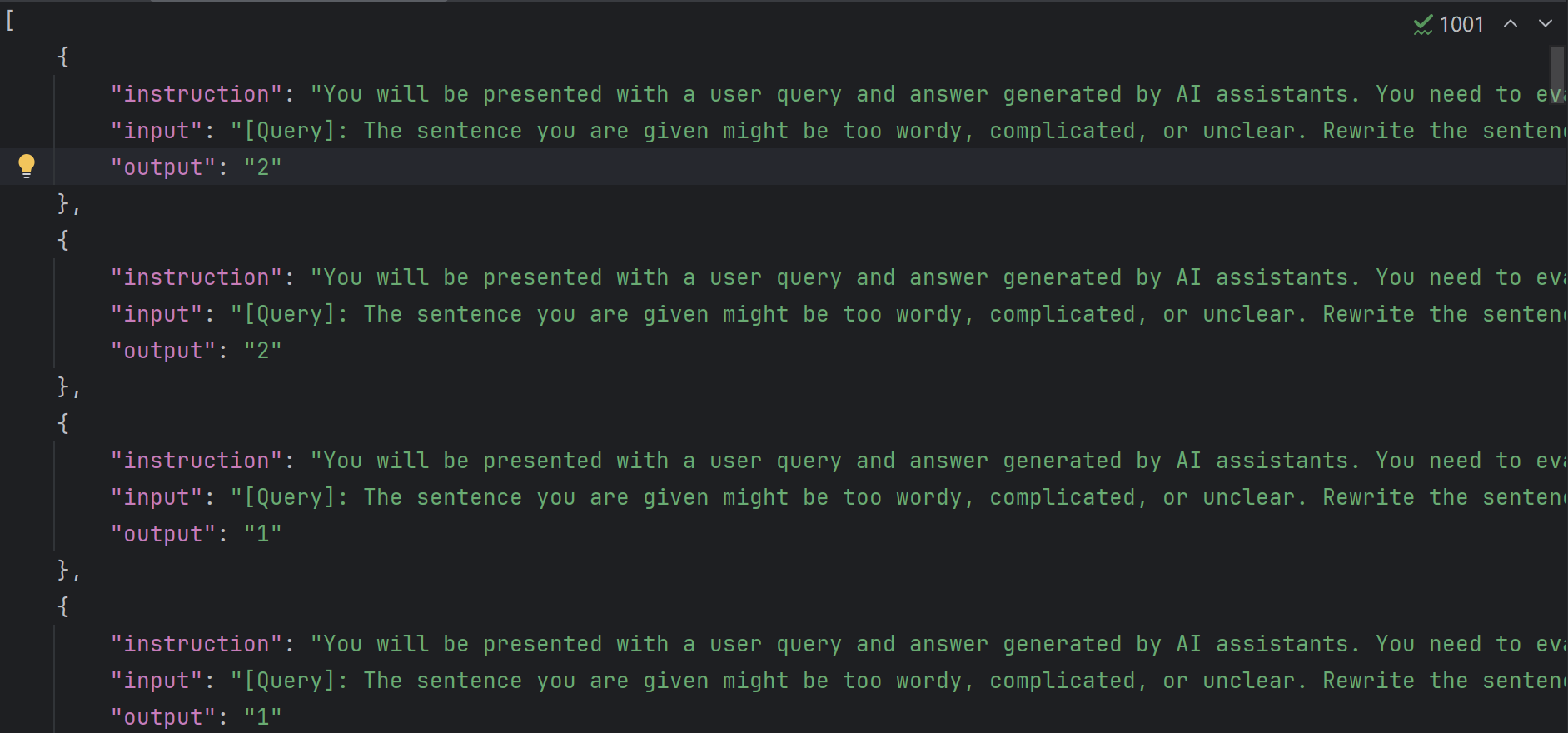
数据在测试前也需要进行处理,首先就是需要把两个回答拆分开,然后更新instruction,大概处理成了下面这个样子,output是前后两个回答相比哪一个更高的结果,测试结果需要先获得得分,然后比较前后的数值的大小,获得比较结果,再和output进行对比获得准确率:
跑分就不展示了